Gathering data from OpenStreetMap with Python
Ever since I started the data science program at Flatiron School, I’ve been looking for ways to incorporate OpenStreetMap into my work. For the uninitiated, OpenStreetMap (OSM) is a free, editable map of the world that’s used by many companies and individuals as an alternative to proprietary solutions like Google Maps. In this article, I will outline all the steps needed to get data from OSM into a Pandas DataFrame. Much credit goes to the writer of this StackOverflow post, who demystified the process for me and wrote much of the code below.
First, import required packages.
import pandas
from geopy.geocoders import Nominatim
import overpyThen input the name of a city to load data from.
city_name = input('Enter city: ')We’d like to select a particular part of the map to load data from, so we instantiate a geocoder object. ‘Nominatim’ is a popular geocoding service used with OSM, and ‘geopy’ provides us with a handy wrapper to request data from the ‘nominatim’ API. Be sure to set the ‘user_agent’ keyword argument to a string uniquely identifying your program.
geolocator = Nominatim(user_agent="our_fancy_program")Now we’ll actually request an area of choice from the map. The method ‘geocode’ is used to find some of the areas matching ‘city_name’ in the entire OSM database. There are three types of items in OSM:
- Nodes – individual points
- Ways – nodes strung together to form a path
- Relations – collections of nodes and ways that have to do with each other
Sometimes cities are represented as nodes as well as relations, but relations are the only items that be used as an area filter. We set the result limit to 3 so we can get all the items with ‘city_name’, then sort through them after.
geo_results = geolocator.geocode(city_name, exactly_one=False, limit=3)Now we use a for loop to sort though the mix and find the first relation.
for r in geo_results:
print(r.address, r.raw.get("osm_type"))
if r.raw.get("osm_type") == "relation":
city = r
breakNext, we’ll be using overpy to interface with our second API, Overpass. The first step in this is calculating the ‘overpass id’ of our selected relation, which is the item’s OSM id number + 3,600,000,000.
area_id = int(city.raw.get("osm_id")) + 3600000000Now we can execute an Overpass API call with Overpass Query Language. I don’t currently have a great understanding of Overpass Query Language, but what I do know is that the parentheses after ‘area’ should contain the ‘overpass id’ of area we’re interested in. I also know that the text inside square brackets is an OSM key-value pair. All information on nodes, ways, and relations is stored in key value pairs like “amenity=atm”. We will keep ‘amenity’ as the key for this excercise, because it is a large category that many map items fall under. Check out the OSM Wiki for more information about tags.
api = overpy.Overpass()
result = api.query("""
area({})->.searchArea;
(
node["amenity"="atm"](area.searchArea);
way["amenity"="atm"](area.searchArea);
relation["amenity"="atm"](area.searchArea);
);
out body;
""".format(area_id))Now that we have our results, we can access lists of fetched items by looking at the nodes, ways, and relations attributes of the ‘result’ object. Checking the type reveals that they are lists.
print(type(result.nodes))
print(type(result.ways))
print(type(result.relations))
Each of the items in the list are special overpy objects.
print(type(result.nodes[0]))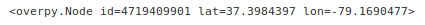
Let’s use the ‘dir’ function to list the attributes and methods of this object.
dir(result.nodes[0])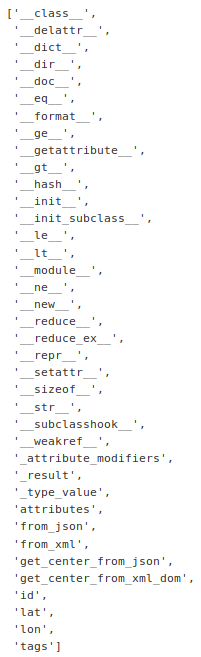
If we look into tags, we find a dictionary of OSM key-value pairs like this one
print(result.nodes[0].tags)
Using the ‘get’ method, we can extract any information about a map item that we want. In this example, we’ll grab name and fee information on a particular ATM in my city.
print(result.nodes[0].tags.get('name'))
print(result.nodes[0].tags.get('fee'))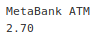
Now we can finally iterate through the tag information and populate a Pandas Dataframe. To make things simple, we’ll just access two pieces of information from the ATM nodes in our area: name and fee.
tag1 = pd.Series()
tag2 = pd.Series()
for i in range(len(result.nodes)):
tag1.at[i] = result.nodes[i].tags.get('name')
tag2.at[i] = result.nodes[i].tags.get('fee')
df = pd.concat([tag1, tag2], axis=1)
df.columns = ['name', 'fee']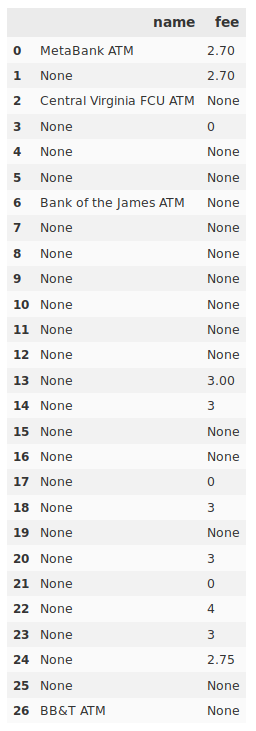
With our information in a Pandas DataFrame, we’re prepared for further analysis. From the number of missing values this turned up in my test case, it also looks like I need to get out and map!
