Building a Tool to Calculate Age from Name Preferences – Step 3/?
Today, I built out the program’s interface in two directions
Command Line
I wrote a sequence to ask questions about name preference and adjust each name’s preference scores. I also added the ability to choose fewer names from each year for processing, as 100 names was time consuming during development. There is also a concern that sorting hundreds of names through human evaluation would be too time consuming, especially if the program is built into a web app. Currently, 10-25 names from each year seems viable.
#input parameters to request the right information
start_year = int(input("Start Year: "))
#quick shortcut that inputs default start and end years if zero is typed
if start_year == 0:
start_year = 1880
end_year = 2018
else:
end_year = 1 + int(input("End Year: "))
gender = input("Gender:").upper()
names_per_year = int(input('Names per year: '))
#create dataframe to final dataset
combined_data = pd.DataFrame()
#iterate through csv files to produce dataframe of top 100 names from each year
for year in range(start_year, end_year):
year_names = pd.read_csv(f'names/yob{year}.txt', header=None, names=["name", 'gender', 'occurrence'])
gendered_year_names = year_names[year_names['gender'] == gender]
gendered_year_names.sort_values(by=['occurrence'], ascending=False, inplace=True)
gendered_year_names_100 = gendered_year_names.head(names_per_year)
combined_data = pd.concat([combined_data, gendered_year_names_100])
#create and print a list of unique names from selected years
unique_names = pd.DataFrame(combined_data['name'].unique())
unique_names.columns = ['name']
unique_names['preference_score'] = pd.Series(np.zeros(len(unique_names)))
print(unique_names)
print(len(unique_names))
#iterate through unique names and rank them by asking
#a series of questions about which name is preferred
preference = ''
while True:
#generate two random indices
name_1_index = np.random.randint(0,len(unique_names))
name_2_index = np.random.randint(0,len(unique_names))
#grab the names behind those indices
name_1 = unique_names.iloc[name_1_index]
name_2 = unique_names.iloc[name_2_index]
#ask user a name preference question
print("Which name do you prefer?\n")
print(f'{name_1[0]}---1---2---3---4---5---{name_2[0]}')
#accept input
preference = input()
#evaluate input
if preference == '1':
#name preference scores are increased and decreased based on choice
unique_names['preference_score'].iloc[name_1_index] += 2
unique_names['preference_score'].iloc[name_2_index] -= 2
elif preference == '2':
unique_names['preference_score'].iloc[name_1_index] += 1
unique_names['preference_score'].iloc[name_2_index] -= 1
elif preference == '3':
pass
elif preference == '4':
unique_names['preference_score'].iloc[name_1_index] -= 1
unique_names['preference_score'].iloc[name_2_index] += 1
elif preference == '5':
unique_names['preference_score'].iloc[name_1_index] -= 2
unique_names['preference_score'].iloc[name_2_index] += 2
elif preference == 'v':
#'v' temporarily exits questioning process to show results so far
print(unique_names.sort_values(by='preference_score'))
print()
elif preference == 'x':
#end loop if user types 'x'
break
else:
#other inputs are invalid
print('***INVALID INPUT***')Web
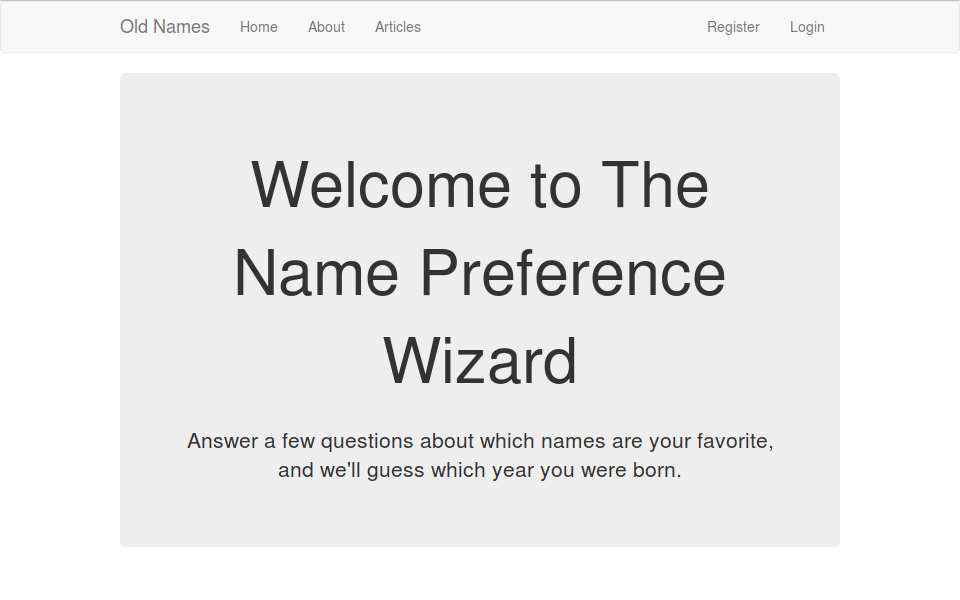
I spent the most time today learning how to use the Flask library with the Bootstrap frontend toolkit. I have a lot to learn regarding rendering templates and web technologies in general, but I got a basic site up and running. The next step is to integrate my existing code so I can enter data through web forms instead of the command line. There are too many files involved to present them in this format, but here’s a screenshot of the site rendered in Firefox. I’m thinking about naming the project ‘Old Names’, ‘OldNames’, or the like.
 </figure>
</figure>
